HBM 사이클은 왜 다를까: 전통 DRAM과 AI 시대의 차이
최종 수정: 작성자: Finyul
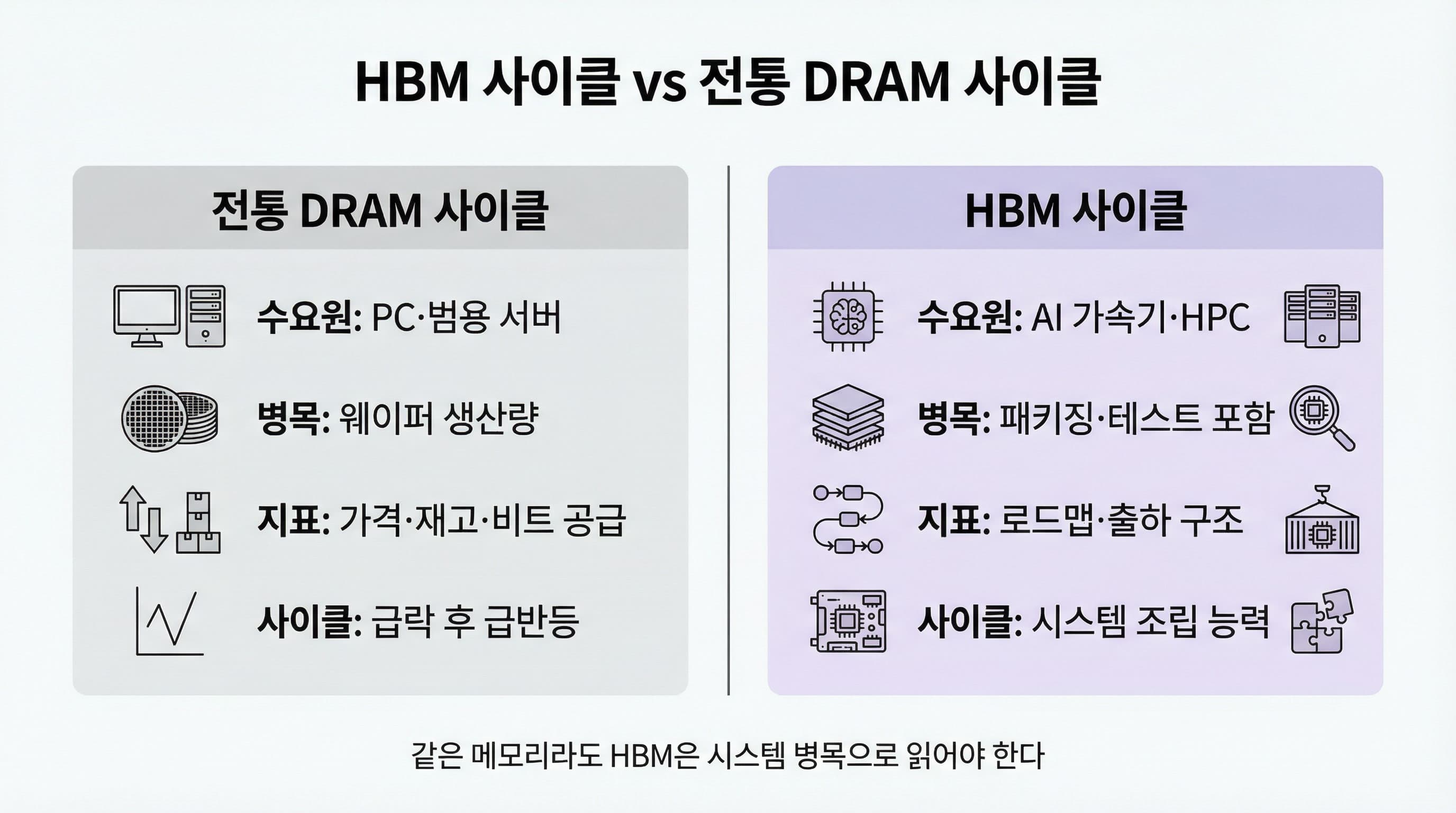
HBM 사이클이 어렵게 느껴지는 이유는, 많은 사람이 이를 전통 DRAM 사이클처럼 읽기 때문입니다. 수요원, 병목 구조, 패키징 의존도 기준으로 차이를 정리합니다.
AI 시대 반도체 사이클의 '질'이 달라졌다: SOX를 Logic·HBM·첨단패키징으로 읽는 법에서 AI 반도체 사이클 전체 구조를 먼저 잡고 오시면 이 글이 더 잘 읽힙니다.
전통 DRAM 사이클은 어떻게 움직였나
이 글에서는 전통 DRAM 사이클이 어떻게 움직여 왔는지, 그리고 HBM 사이클과 무엇이 다른지 설명합니다.
DRAM은 전원이 꺼지면 저장된 데이터가 사라지는 메모리입니다. (이처럼 전원이 없으면 데이터가 지워지는 메모리를 휘발성 메모리라고 부릅니다.) PC·스마트폰·서버 같은 일반 컴퓨팅 기기에 거의 빠짐없이 들어갑니다.
전통 DRAM 사이클은 반복되는 패턴이 있었습니다.
- 수요가 줄면 창고에 재고가 쌓입니다.
- 재고가 쌓이면 가격이 내려갑니다.
- 가격이 내려가면 제조사가 생산량을 줄입니다(감산).
- 재고가 다시 줄면 가격이 오르고 실적도 회복됩니다.
2023년 글로벌 반도체 시장이 8.2% 줄었다가 2024년에 메모리 매출이 78.9% 급반등한 것이 대표적인 예입니다.([1]) 1년 만에 하락과 반등이 교차하는 전형적인 메모리 업황의 모습입니다.
이 사이클에서 핵심 지표는 가격, 재고, 비트 공급량(생산되는 메모리의 총 데이터 용량)이었습니다.
메모리 시장 규모 (2024~2026)
실적 전망 (WSTS Autumn 2025)
HBM 세대별 대역폭 (GB/s)
HBM2E → HBM4: 7배 이상 대역폭 성장
HBM은 DRAM인데, 왜 해석은 달라질까
HBM은 “더 비싼 DRAM”이 아니라 “AI용 시스템 메모리”에 가깝다
HBM도 큰 틀에서는 DRAM입니다. 다만 구조가 다릅니다. 삼성은 HBM을 TSV 기반 적층 기술이 들어간 초고대역폭 메모리라고 설명하고, AI 학습과 고성능 컴퓨팅에 최적화된다고 밝힙니다.([4])
전통 DRAM이 넓은 창고라면, HBM은 초고속 물류 고속도로에 가깝습니다. 저장 자체보다 얼마나 빨리 데이터를 밀어 넣고 빼내느냐가 더 중요합니다.
숫자로 보는 HBM 세대별 대역폭 도약
Micron은 HBM3E가 초당 1.2TB(테라바이트) 이상 데이터를 전송할 수 있다고 설명합니다. 일반 SSD(저장 장치)보다 수십 배 빠른 속도입니다.([2])
Samsung은 HBM4가 최대 3,300GB/s 대역폭과 2,048개 I/O(데이터가 드나드는 통로 수)를 지원한다고 밝힙니다. 4nm 로직 베이스다이(연산 기능을 더한 하부 칩)를 사용해 전력 효율을 최대 40% 높일 수 있다고 합니다.([4])
SK hynix도 HBM4에서 2,048개 I/O와 2.8TB/s 이상 대역폭을 제시합니다.([3])
이 수치들이 말해주는 건 한 가지입니다. HBM은 이미 단순한 메모리가 아니라 AI 시스템에 맞춘 고성능 부품이 됐습니다.대역폭, 전력 효율, 로직 베이스다이, 적층 기술을 함께 봐야 합니다.
HBM이 시스템 병목이 되는 구조
전통 DRAM은 가격·재고의 문제로 많이 읽혔지만, HBM은 AI 시스템 병목과 함께 움직인다.
AI 가속기 수요
연산칩이 먼저 빨라진다
AI 서버는 더 많은 연산을 요구하고, 로직 칩 성능이 먼저 올라간다.
HBM 필요
메모리 대역폭이 병목이 된다
HBM은 AI용 고대역폭 메모리로, 빠른 연산칩에 데이터를 제때 공급하는 역할을 맡는다.
CoWoS·2.5D/3D
로직과 HBM을 실제로 묶어야 한다
큰 silicon interposer와 고밀도 연결이 있어야 로직 chiplet과 HBM cube가 함께 동작한다.
테스트·열·전력
패키징 뒤에도 검증이 남는다
열, 전력, 신호 무결성, 테스트를 통과해야 실제 출하와 매출이 가능해진다.
실적 반영
그래서 HBM은 시스템 사이클처럼 움직인다
HBM 수요는 단순 메모리 가격보다 AI 시스템 조립 능력과 공급망 병목에 더 민감하다.
✓HBM은 DRAM의 한 종류지만, 해석 프레임은 다르다.
✓병목은 메모리 공장 안이 아니라 패키징·테스트까지 확장된다.
✓HBM은 가격표보다 시스템 연결 구조를 봐야 읽힌다.
HBM 사이클이 전통 DRAM과 다른 진짜 이유
1. 수요의 출발점이 다르다
전통 DRAM은 PC·스마트폰·범용 서버처럼 넓은 시장의 수요를 따라 움직였습니다. 많은 기업과 개인이 새 기기를 살 때 자연스럽게 메모리 수요가 늘었습니다.
반면 HBM은 AI 가속기(엔비디아 GPU 같은 AI 연산 전용 칩)와 고성능 컴퓨팅 시스템에서 수요가 납니다. 특정 고성능 장비에만 쓰이는 부품이라서, 일반 메모리 시장과는 움직임이 다릅니다.
WSTS(세계 반도체 통계 기관)에 따르면 메모리 매출은 2024년 1,655억달러에서 2025년 2,116억달러로 늘었고, 2026년에는 2,948억달러까지 커질 것으로 전망됩니다. AI 관련 응용과 데이터센터 인프라 수요가 이 성장을 이끌었다고 WSTS는 설명합니다.([7])
2. 병목이 메모리 공장 안에만 있지 않다
전통 DRAM은 공장에서 메모리를 많이 만들면 공급이 늘고, 가격이 떨어지는 구조였습니다.
HBM은 다릅니다. 메모리 공장이 잘 돌아가도 그것만으로는 부족합니다. 실제로 출하되려면 CoWoS(AI 칩과 HBM을 한 판 위에 올리는 첨단 조립 공정)라는 과정이 필요합니다. TSMC는 CoWoS를 AI와 슈퍼컴퓨팅용 초고성능 패키지 기술이라고 설명합니다. 큰 실리콘 인터포저(칩들을 연결해주는 특수 기판) 위에 로직 칩렛(연산 칩 조각)과 HBM을 함께 올리는 방식입니다.([5])
이 구조에서는 패키징, 인터포저, 열 관리, 전력, 테스트가 모두 같이 걸립니다. 그래서 HBM 사이클은 단순한 “메모리 업황”이 아니라, “AI 시스템 조립 능력”으로 봐야 합니다. CoWoS·OSAT·테스트가 실제로 어떤 구조로 묶이는지는 첨단 패키징과 OSAT는 왜 병목이 되었나에서 단계별로 확인할 수 있습니다.
3. 공개 통계가 HBM만 따로 보여주지 않는다
공개 산업 통계는 대부분 메모리 전체를 한 덩어리로 보여줍니다. HBM만 따로 떼어서 보여주지 않습니다.
그래서 “메모리 업황이 좋다”는 말만 듣고, HBM도 자동으로 같은 속도로 좋다고 해석하면 오류가 생깁니다. HBM과 일반 DRAM은 수요원도 다르고, 병목 구조도 다릅니다.
통계 숫자 하나만 보는 것보다, 각 벤더(제조사)의 제품 로드맵과 패키징 업체의 생산 계획을 함께 봐야 더 정확합니다.
| 비교 항목 | 전통 DRAM 사이클 | HBM 사이클 | 근거 데이터·메모 |
|---|---|---|---|
| 주요 수요원 | PC, 스마트폰, 범용 서버 등 넓은 평균 수요의 영향을 크게 받음 | AI 가속기, HPC, AI 서버처럼 특정 시스템 수요에 더 강하게 묶임 | WSTS: 2025 성장은 AI 관련 Logic·Memory와 데이터센터 수요 주도 |
| 업황 해석 중심 | 재고, ASP, bit shipment, 감산 여부 | 대역폭, I/O, 전력 효율, 적층, 패키징 수용 능력 | Micron HBM3E >1.2TB/s · Samsung HBM4 up to 3,300GB/s, 2,048 I/O |
| 대표 병목 | 공급 과잉/부족, 가격 하락·반등 | HBM 생산뿐 아니라 CoWoS, 인터포저, 테스트, 열·전력 관리 | TSMC CoWoS-S: logic chiplets + HBM cubes를 큰 실리콘 인터포저 위에 수용 |
| 패키징 의존도 | 상대적으로 낮음 | 매우 높음 | ASE: HBM 탑재 2.5D IC 패키지 양산 경험 강조 |
| 공개 통계 가시성 | 산업 통계로 비교적 해석하기 쉬움 | 공개 시장 통계는 Memory 전체, HBM 단독 통계는 제한적 | WSTS 공개표는 Memory 총액만 제공 |
| 최근 숫자 | 2024 Memory +78.9%, DRAM +82.6% 급반등 패턴 | 2024 $165.5B → 2025 $211.6B → 2026 $294.8B + HBM 1.2~3.3TB/s | HBM은 메모리 매출 증가와 별도로 시스템 성능 병목 축으로 읽어야 함 |
HBM 사이클을 볼 때 꼭 확인할 4가지
- HBM을 DRAM 평균으로 보지 말 것. 같은 메모리라도 용도와 병목 구조가 다릅니다.
- 로직과 함께 볼 것. HBM은 AI 가속기 옆에서 가치가 커지기 때문에 로직 없이 단독으로 읽으면 반쪽 해석이 됩니다.
- 패키징과 테스트를 같이 볼 것. CoWoS나 2.5D·3D 패키징이 막히면 HBM 수요가 있어도 출하 속도가 늦어집니다.
- HBM 전용 숫자가 부족하다는 점을 인정할 것. 산업 통계, 메모리 업체 로드맵, 패키징 업체 발표를 함께 봐야 합니다.
공개 지표만으로 HBM 과열을 판단하기 어려울 때, 리드타임·가격 소문·가동률 착시를 체크리스트로 점검하는 방법은 AI 반도체 과열 신호 7가지 체크리스트에 정리해 두었습니다.
FAQ
자주 묻는 질문
- HBM은 DRAM과 어떻게 다른가요?
- HBM도 DRAM의 한 종류지만, TSV 기반 수직 적층 구조로 만들어 대역폭이 일반 DRAM보다 수배~수십배 높습니다. AI와 HPC 시스템에 최적화된 설계입니다.
- HBM 사이클을 볼 때 왜 메모리 가격표만 보면 안 되나요?
- HBM은 CoWoS 같은 첨단 패키징, 인터포저, 테스트가 묶인 시스템 부품이기 때문입니다. 메모리 공장 생산량만 늘어도 패키징이 막히면 출하가 안 됩니다.
- WSTS 통계에서 HBM만 따로 볼 수 있나요?
- 아닙니다. WSTS 공개표는 Memory 전체 카테고리로 제공됩니다. HBM 단독 통계는 공개되지 않으므로, 벤더 제품 로드맵과 패키징 업체 발표를 함께 봐야 합니다.
- HBM4는 HBM3E와 어떤 차이가 있나요?
- HBM4는 SK hynix 기준 2.8TB/s 이상, Samsung 기준 최대 3,300GB/s 대역폭으로 HBM3E(1.2TB/s+)보다 훨씬 높습니다. 또 4nm 로직 베이스다이와 2,048 I/O 등 시스템 통합 특성이 강화됩니다.
결론: HBM은 메모리이지만, 사이클은 시스템처럼 움직인다
전통 DRAM 사이클은 재고와 가격, 공급량을 중심으로 읽어도 어느 정도 맞았습니다. HBM 사이클은 그 틀만으로는 부족합니다. HBM은 DRAM이면서도, AI 가속기와 함께 움직이고, 패키징과 테스트에 묶이고, 전력과 대역폭까지 같이 봐야 하는 시스템 메모리에 가까워졌습니다. “메모리 업황이 좋은가”보다“AI 시스템 병목이 지금 HBM 쪽에 얼마나 집중돼 있는가”를 먼저 보는 편이 훨씬 정확합니다.