트레이딩 로그 설계 완전 가이드: 로그·리플레이·리뷰로 “왜 그 결정을 했는지” 남기는 법
최종 수정: 작성자: Finyul
전략이 흔들릴 때 진짜 문제는 “수익이 줄었다”가 아니라 원인을 못 찾는 것입니다. 이 글은 로그 구조(필드/스키마) → 리플레이(재현) → 리뷰 루틴(개선)으로 AI 트레이딩을 증거 기반으로 운영하는 방법을 제공합니다.
전체 폐루프(분석→예측→결정→실행) 큰 그림이 궁금하면 LLM 멀티에이전트 투자 시스템(MAS) 완전 가이드를 참고하세요.
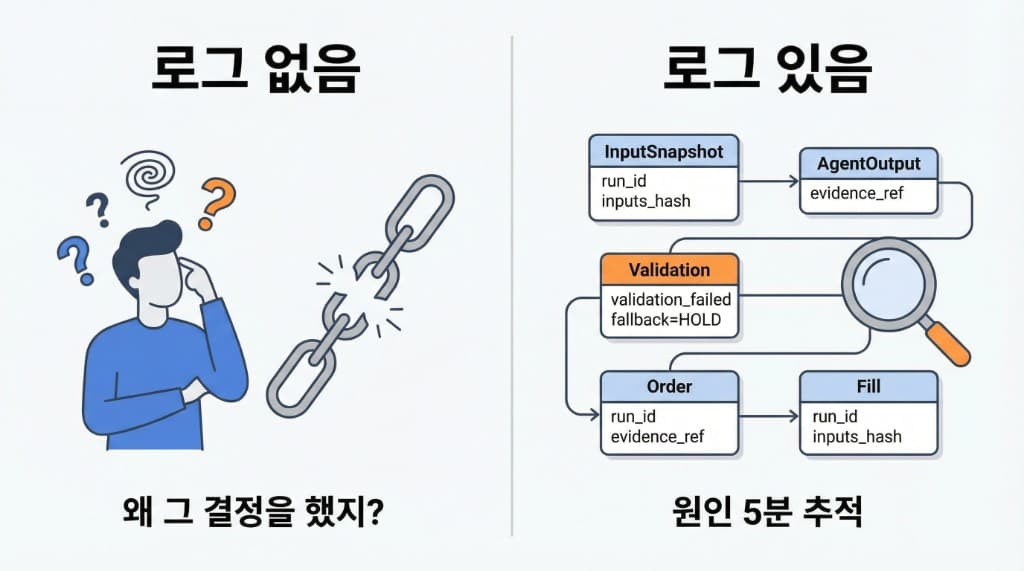
왜 로그가 ‘성과’보다 중요할 때가 많나: 재현·디버깅·감사의 기반
AI/멀티에이전트 시스템에서 성과가 나빠졌을 때, 원인은 보통 세 곳 중 하나입니다.
- 입력이 바뀌었는데 모르고 있다(데이터 버전/윈도우/누락)
- 출력이 흔들렸는데 “왜 흔들렸는지”가 없다(스키마/검증/재시도 기록 부재)
- 실행에서 깨졌는데 백테스트처럼 생각한다(체결 실패/부분체결/슬리피지)
로그가 없으면 결국 “뉴스 때문인가?”, “지표 때문인가?”, “내가 멘탈이 흔들렸나?”로 끝납니다.
| 비교 항목 | 로그 없음 | 로그 있음 |
|---|---|---|
| 디버깅 시간 | 길다 | 짧다 |
| 재현성 | 낮음 | 높음 |
| 리뷰 품질 | 낮음 | 높음 |
| 규칙 준수 | 확인 어려움 | 검증 가능 |
| 책임 추적 | 불가 | 가능 |
용어 3개만 정리해도 설계가 빨라진다
| 용어 | 정의 | 구성·목적 | 효과 |
|---|---|---|---|
| 관측성(Observability) | 운영 중 시스템이 “보이게” 만드는 것 | 로그 / 트레이스 / 메트릭 | 원인·상태를 언제든 확인 가능 |
| 리플레이(Replay) | 동일 입력·동일 설정으로 다시 실행해 결과를 재현하는 것 | 원인 파악·재현성 검증 | 같은 입력이면 같은 결과 보장 |
| 감사(Audit Trail) | “왜 그런 결정을 했는지” 근거를 나중에 증명 가능한 형태로 남기는 것 | 규칙 준수·개선 근거 | 결정 근거·규칙 위반 추적 가능 |
보이게 → 재현하게 → 증명하게
좋은 로그의 원칙 7개: 무엇을 남길지부터 정하라
1) 5W1H로 필드 설계를 시작한다
- When: 언제(as_of, timestamp)
- What: 무엇을 봤나(input snapshot)
- Who: 누가 판단했나(agent/model/prompt)
- Why: 왜 그렇게 했나(rationale/evidence)
- How: 어떻게 검증했나(validation/retry)
- Result: 결과가 어땠나(order/fill/cost)
2) 입력 스냅샷은 “해시”로 고정한다
데이터가 바뀌면 결과도 바뀝니다. inputs_hash(예: sha256)로 “그날 봤던 데이터”를 고정하세요.
3) 출력은 스키마로 고정한다(흔들림 차단)
에이전트가 텍스트로 말하면 운영에서 다 무너집니다. JSON 스키마 + enum + 필수 필드로 “형식 환각”부터 막으세요. LLM 에이전트 출력 표준화: JSON 스키마 템플릿으로 분석→예측→결정 연결하기를 참고하세요.
4) 검증(Validation) 결과를 반드시 남긴다
schema_valid / domain_valid / failed_rule / retry_count / fallback(HOLD) 이유. 이게 없으면 “왜 HOLD였는지”도 못 찾습니다.
5) 실행은 백테스트가 아니다: 주문/체결을 별도 이벤트로 남긴다
주문 생성(Order)과 체결(Fill)은 다릅니다. 부분체결/거부/지연은 실행 로그에만 있습니다.
6) 변경 이력은 run_id로 분리한다(버전 관리)
모델/프롬프트/파라미터/데이터 소스가 바뀌면 같은 전략이 아닙니다. run_id로 분리하세요.
7) 사람용 요약과 기계용 원문을 분리 저장한다
“요약만” 남기면 나중에 검증이 안 됩니다. 원문 JSON은 그대로 저장하고, 요약은 별도 컬럼으로 두세요.
| 원칙 | 이유 | 실수 사례 | 권장 필드 |
|---|---|---|---|
| 5W1H로 설계 | 누락 시 리뷰/리플레이 불가 | timestamp 없이 요약만 저장 | as_of, input_ref, agent, rationale, validation, order_id |
| inputs_hash로 입력 고정 | 데이터 변경 시 결과 달라짐 | inputs_hash 미저장 | inputs_hash (sha256 등) |
| 출력 스키마/enum 고정 | 형식 흔들림 → 파싱/검증 붕괴 | 텍스트 출력만 저장 | schema_id, output(JSON 원문) |
| 검증결과·재시도·폴백 기록 | HOLD/폴백 사유 추적 | failed_rule 미기록 | schema_valid, domain_valid, failed_rule, retry_count |
| 주문/체결 분리 기록 | 실행 현실 반영 | Order만 있고 Fill 없음 | Order 이벤트, Fill 이벤트(filled_qty, avg_price, fee_rate) |
| 모델/프롬프트/파라미터 버전 분리(run_id) | 버전/실험 분리 | 버전 섞여 리플레이 불가 | run_id (모든 이벤트 공통) |
| 원문(JSON)과 요약 분리 | 검증 시 원문 필요 | 요약만 저장 후 재검증 불가 | summary(텍스트), raw(JSON) |
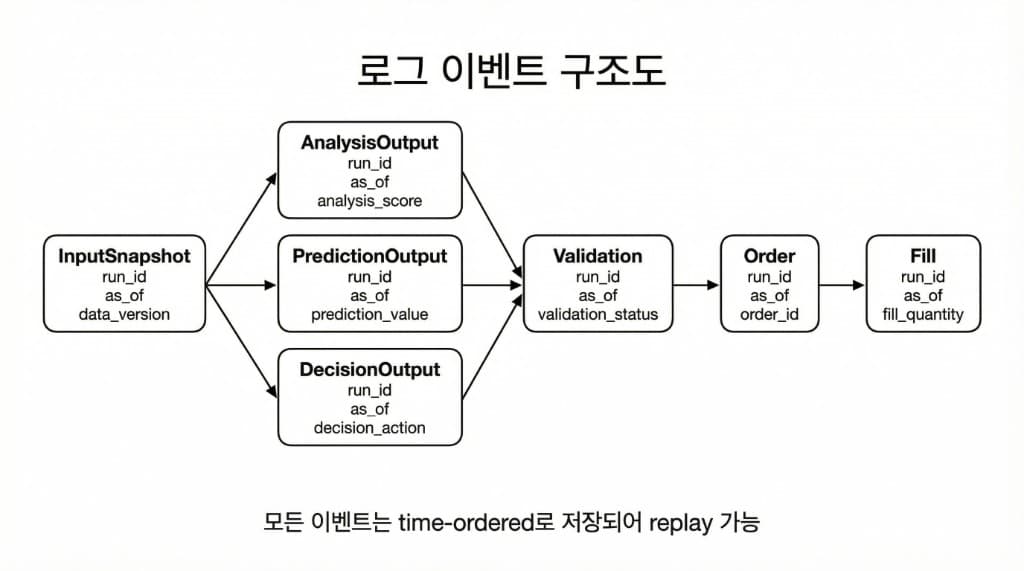
로그 스키마 핵심: 이벤트 기반 LogEvent로 쪼개라
“거대한 한 줄 로그”는 리뷰할수록 지옥입니다. 아래처럼 이벤트 단위로 쪼개면 리플레이가 쉬워집니다.
| 이벤트 타입 | 필수 필드 | 예시 | 저장 위치 |
|---|---|---|---|
| InputSnapshot | run_id, as_of, asset, inputs_hash, data_window | data_window: last_60d | JSONL / DB |
| AgentOutput | run_id, as_of, asset, schema_id, agent, output | prediction → T5 up/down/side | JSONL / DB |
| Validation | run_id, as_of, schema_valid, domain_valid, retry_count | true, true, 0 | JSONL / DB |
| Decision | run_id, as_of, action, rationale, constraints_applied | increase_20, ["T5 up 우세"] | JSONL / DB |
| Order | run_id, as_of, side, qty, order_type | BUY, qty, MKT | JSONL / DB |
| Fill | run_id, as_of, filled_qty, avg_price, fee_rate | filled_qty, avg_price, fee_rate | JSONL / DB |
복붙용 미니 예시(JSONL 느낌)
InputSnapshot2025-01-10_REIT_X_0007
{
"event": "InputSnapshot",
"run_id": "2025-01-10_REIT_X_0007",
"as_of": "2025-01-10T09:05:00+09:00",
"asset": "REIT_X",
"inputs_hash": "sha256:...",
"data_window": "last_60d"
}AgentOutput2025-01-10_REIT_X_0007
{
"event": "AgentOutput",
"agent": "prediction",
"schema_id": "prediction_output_v1",
"run_id": "2025-01-10_REIT_X_0007",
"horizons": [
"T1",
"T5",
"T20"
],
"output": {
"T5": {
"up": 0.44,
"down": 0.18,
"side": 0.38
}
}
}Validation2025-01-10_REIT_X_0007
{
"event": "Validation",
"run_id": "2025-01-10_REIT_X_0007",
"schema_valid": true,
"domain_valid": true,
"retry_count": 0
}Decision2025-01-10_REIT_X_0007
{
"event": "Decision",
"run_id": "2025-01-10_REIT_X_0007",
"action": "increase_20",
"rationale": [
"T5 up 우세",
"cap/step OK"
],
"constraints_applied": [
"position_cap",
"step_size"
]
}Order2025-01-10_REIT_X_0007
{
"event": "Order",
"run_id": "2025-01-10_REIT_X_0007",
"side": "BUY",
"qty": 100,
"order_type": "MKT"
}Fill2025-01-10_REIT_X_0007
{
"event": "Fill",
"run_id": "2025-01-10_REIT_X_0007",
"filled_qty": 80,
"avg_price": 101.2,
"fee_rate": 0.0003
}
저장/조회 설계: “남긴 로그를 찾을 수 있어야” 의미가 있다
- JSONL: 개발/디버깅 친화(원문 그대로)
- Parquet: 분석/집계 친화(대규모 백테스트 로그)
- DB(또는 검색 인덱스): 운영 조회 친화(대시보드, 필터링)
권장 파티셔닝 키: date / strategy / asset / run_id
리플레이(Replay): “같은 입력이면 같은 결과”를 보장하는 체크리스트
리플레이가 깨지는 가장 흔한 원인은 데이터/버전/랜덤성입니다.
리플레이 3종
- Full replay: 입력부터 실행까지 전체 재실행
- Step replay: 분석만/예측만/결정만 단계별 재실행(원인 파악에 최고)
- What-if: 가정(가중치/제약/임계값)만 바꿔 비교
1) 입력 고정
inputs_hash·모델/프롬프트 버전·파라미터 스냅샷 동일
리플레이가 깨지는 가장 흔한 원인: 데이터/버전/랜덤성
- inputs_hash 동일
- 모델·프롬프트·파라미터 버전 동일
2) 단계 재실행
Full replay / Step replay(분석만·예측만·결정만) / What-if
Step replay가 원인 파악에 가장 유리
- analysis / prediction / decision 단계별 재실행
- What-if: 가중치·제약·임계값만 변경 비교
3) 차이(diff) 분석
재실행 결과와 당시 결과 비교 → 어디서 달라졌는지 확인
validation/retry 정책 동일할 것(HOLD 폴백 포함)
- 재실행 결과 vs 당시 결과 diff
- 변경점 요약으로 원인 특정
입력 고정 → 단계 재실행 → diff 분석. inputs_hash 동일 · 버전 동일 · 파라미터 스냅샷 동일 · validation 정책 동일
리플레이 체크리스트(필수)
- inputs_hash 동일
- 모델/프롬프트 버전 동일
- 파라미터 스냅샷 동일(윈도우/임계값/가중치)
- validation/retry 정책 동일(HOLD 폴백 포함)
리뷰 루틴: 로그는 쌓이면 쓰레기, 템플릿이 있어야 자산
데일리(1~3분): 3줄 리뷰
- 오늘의 최종 결정(action)
- 근거(evidence) 1줄
- 규칙 위반/폴백(HOLD) 여부
주간(30분): 5개만 본다
| 항목 | 정의 | 기준선 | 다음 액션 |
|---|---|---|---|
| 성과(수익/낙폭) | 주간 수익률·최대낙폭 등 | — | — |
| 규칙 준수율(%) | 검증 통과·제약 준수 비율 | — | — |
| 결정 변경 횟수(주간) | 같은 일/세션 내 최종 결정이 바뀐 횟수의 주간 합 | — | — |
| 폴백(HOLD) 비율 및 사유 Top3 | 검증 실패 또는 Stop rule로 실행 보류한 비율·사유 | — | — |
| 실패 유형 Top3 | 파싱/스키마/도메인/실행 실패 건수·유형 | — | — |
로그가 “원인 추적 시간”을 줄이는 실제 운영 시나리오
Before(로그 없음)
“뉴스가 불안해서 손절했는데, 나중에 보니 기술적으론 계속 추세였다” → 원인 추정만 반복.
After(로그/검증 있음)
- AgentOutput에서 뉴스 신호 evidence_ref가 비었음 → 근거 부족
- Validation에서 failed_rule=evidence_missing → HOLD 폴백이 맞았음
- 다음 주에는 “뉴스 신호의 품질 규칙”을 강화(중복/출처 불명 강등)
즉, ‘감’이 아니라 로그가 다음 개선을 결정합니다.
운영 품질 지표 3종 정의
재현 실패율 · 검증 실패율 · 폴백 사유 Top5. 내부 로그 집계로 정의·추적.
| 지표 | 정의 | 집계(내부 로그) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 재현 실패율 | 동일 inputs_hash·동일 설정으로 재실행 시 출력/결정이 원본과 불일치한 run 비율 | 4주 572 run 중 12건 불일치 → 2.1% | ||||||||||
| 검증 실패율 | schema_valid 또는 domain_valid가 false인 AgentOutput 비율 | 4주 584건 중 31건 실패 → 5.3% | ||||||||||
| 폴백 사유 Top5 | Decision=HOLD 또는 실행 보류된 사유(Validation/Stop rule)별 건수 |
|
출처: 내부 로그(운영 환경 run_id·Validation·Decision 이벤트 집계).
한계와 주의사항
- 로그가 완벽해도 입력 데이터가 틀리면 결과도 틀립니다(입력 품질이 최상위).
- 실거래는 체결/슬리피지/지연이 있어 백테스트와 다릅니다 → Order/Fill 로그 필수
- 계정/개인정보 등 민감 데이터는 마스킹/접근권한 분리/보관기간 정책이 필요합니다.
외부 참고:
- NIST AI RMF— AI 리스크 관리 프레임워크
- OpenTelemetry/CNCF— 관측성(로그·트레이스·메트릭) 표준
- SEC · FINRA— 알고리즘·자동매매 리스크 고지 가이드 참고
FAQ
자주 묻는 질문
- 로그는 어디까지 남겨야 하나요?
- 리플레이에 필요한 "입력 스냅샷·출력 원문·검증 결과·주문/체결"까지는 필수입니다. 요약만 남기면 나중에 못 고칩니다.
- 리플레이가 안 되는 가장 흔한 이유는?
- 데이터가 업데이트됐는데 inputs_hash를 안 남긴 경우, 또는 모델/프롬프트 버전이 섞인 경우입니다.
- 멀티에이전트에서 누가 문제였는지 어떻게 찾나요?
- Step replay(단계별 재실행) + Validation 로그(어떤 규칙이 깨졌는지) 조합이 가장 빠릅니다.
결론: “로그→리플레이→리뷰”가 돌아가면 시스템은 자동으로 강해진다
- 입력을 해시로 고정하고
- 출력은 스키마로 고정하고
- 검증/재시도/폴백을 기록하고
- 주문/체결까지 현실을 남기고
- 주간 리뷰로 한 번에 하나씩 개선하세요.
전체 구조로 확장하려면 LLM 멀티에이전트 투자 시스템(MAS) 완전 가이드. 출력 흔들림부터 잡으려면 LLM 에이전트 출력 표준화: JSON 스키마 템플릿으로 분석→예측→결정 연결하기를 참고하세요.