LLM 비용 비교: 대형 모델 API vs 소형 모델 파인튜닝, 트레이딩 시스템 선택 프레임
최종 수정: 작성자: Finyul
“지금 구조로 계속 API를 쓸지, 작은 모델을 파인튜닝해서 갈지” 고민이 생기는 순간은 보통 하나입니다. 호출량이 늘었는데, 비용·지연·리스크가 한꺼번에 체감될 때. 이 글은 대형 모델 API vs 소형 모델 파인튜닝을 감으로 고르지 않도록, 비용 계산식 + 트래픽/호출 구조 기준 + 리스크 체크리스트로 결정하게 만드는 프레임을 제공합니다.
큰 그림(폐루프 설계)이 먼저라면 LLM 멀티에이전트 투자 시스템(MAS) 완전 가이드를 참고하세요.
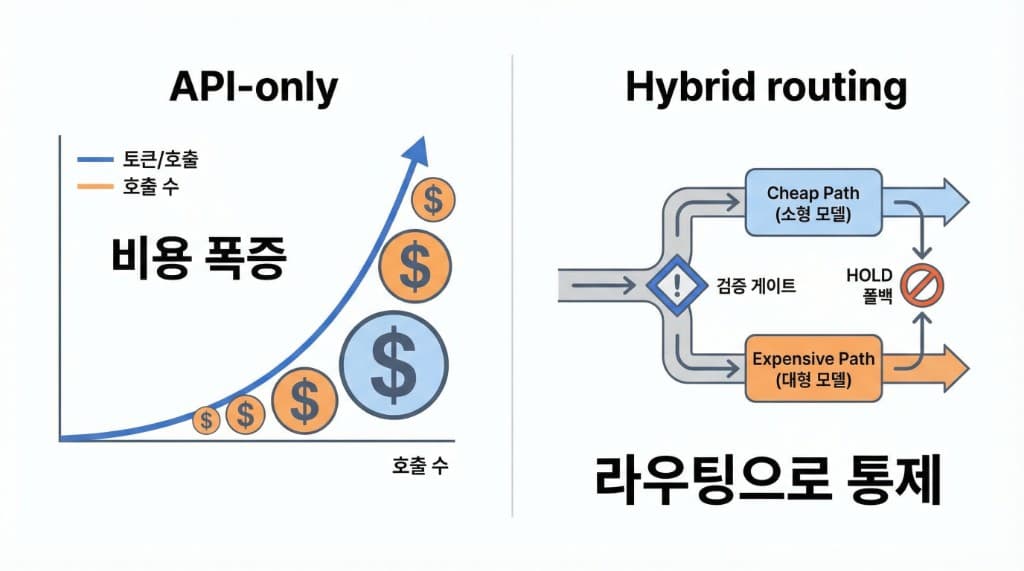
1) 결론부터: 어떤 선택이 유리한지 3문장으로 정리
- 트래픽(토큰·호출 수)이 작거나, 요구가 자주 바뀌면 → 대형 모델 API가 빠르다. (실험 속도/품질)
- 규칙화된 업무가 많고 트래픽이 크면 → 소형 모델(파인튜닝/호스팅) 또는 하이브리드가 유리해진다. (단가/지연)
- 리스크(데이터/컴플라이언스/장애 허용) 요구가 높으면 → “무조건 한 쪽”이 아니라 라우팅+게이트가 정답인 경우가 많다.
2) 비용을 “3층”으로 쪼개면 선택이 쉬워진다
트레이딩 시스템 비용은 모델 가격표만 보면 계속 헷갈립니다. (1) 추론, (2) 학습, (3) 운영으로 쪼개면 됩니다.
| 비용 층 | 대형 API | 소형 파인튜닝 | 하이브리드 |
|---|---|---|---|
| 추론비 | 입력·출력 토큰 단가 도구 호출 비용 | GPU/서버 월비용 관측성·서빙 비용 | API 비용 + 자체 서빙 비용 혼합 |
| 학습비 | 파인튜닝 시 학습 토큰 단가 | GPU 시간 × 단가 데이터 구축 비용 | 소형 쪽 학습 (선택) API 파인튜닝 |
| 운영비 | SLA/레이트리밋 대응 캐싱·배치 설계 | 배포·오토스케일 장애 대응·보안 모델 드리프트 모니터링 | 라우팅·폴백·캐시 모니터링 통합 |
(1) 추론비(Inference)
- API: (입력 토큰 × 입력단가) + (출력 토큰 × 출력단가) + (도구 호출 비용).예) OpenAI 기준, gpt-4o는 입력 $4.25/1M, 출력 $17/1M로 표기됩니다.
- 소형 호스팅: GPU/서버 비용 + 관측성/서빙 비용.예) AWS g5.xlarge(1×NVIDIA A10G) 온디맨드는 약 $1.0060/시간(≈ $734.38/월)로 표기됩니다(지역/OS에 따라 변동).
(2) 학습비(Training / Fine-tuning)
“내가 파인튜닝을 할 건지”는 비용 구조를 바꿉니다.
예) OpenAI 파인튜닝 가격표에서 GPT-4.1 nano 학습이 $1.50/1M tokens, 추론 입력/출력도 별도로 표시됩니다.
오픈소스 파인튜닝은 “토큰당 가격표”가 아니라 GPU 시간 × 시간당 단가 + 데이터 구축 비용으로 계산합니다.
(3) 운영비(Ops)
- API: SLA/레이트리밋/요금폭탄 방지(캐싱·배치) 설계가 운영비.
- 자체 호스팅: 배포, 오토스케일링, 장애 대응, 보안, 모델 드리프트 모니터링이 운영비.
3) 바로 써먹는 비용 계산식(로그만 있으면 끝)
핵심은 “월 토큰/호출량”을 로그에서 측정하는 겁니다. 그 다음은 산수입니다.
| 서비스 | 입력 단가 | 출력 단가 | 비고 | 출처 |
|---|---|---|---|---|
| OpenAI gpt-4o Standard | $4.25/1M | $17.00/1M | Cached input $2.125/1M | OpenAI API Pricing |
| Google Gemini 2.5 Pro | $1.25/1M | $10.00/1M | 프롬프트 ≤200k; >200k 구간 단가 별도 | Google AI Pricing |
| AWS EC2 g5.xlarge | $1.0060/hr | ~$734.38/월 | us-east-1 온디맨드 | AWS EC2 On-Demand |
API 비용(월)
- Cost ≈ (Tin/1M × Pin) + (Tout/1M × Pout) + ToolCost
- Pin/Pout는 모델별 단가(공식 가격표), Tin/Tout는 운영 로그의 토큰 집계.
파인튜닝(또는 자체 호스팅) 비용(월)
- Cost ≈ (서빙 GPU 월비용 + 인프라/관측성) + (학습비를 월로 나눈 감가)
- 예) g5.xlarge 온디맨드 약 $734.38/월(24/7 기준). 여기에 스토리지/네트워크/모니터링/엔지니어링 시간을 얹어야 “진짜 비용”이 됩니다.
가장 실용적인 지표: “브레이크이븐(손익분기) 토큰”
- Break-even Tokens(월) ≈ (자체호스팅 월 고정비) ÷ (API의 1M토큰당 비용) × 1M
- 여기서 “API의 1M토큰당 비용”은 출력/입력 비율(Tout/Tin)에 따라 달라집니다. → 그래서 먼저 로그로 Tout/Tin을 뽑는 것이 제일 중요합니다.
브레이크이븐: 69.08235294117647M tokens/월 (API 비용 = 자체호스팅 고정비)
4) 성능: “큰 모델이 항상 더 낫다”는 가정이 깨지는 지점
트레이딩 시스템은 범용 지식보다 일관된 구조화 출력 + 제약 준수 + 재현성이 성능을 결정합니다. 중국 공모 REITs 멀티에이전트 시스템 연구는 예측 에이전트에서 대형 범용 모델(DeepSeek-R1) 직접 호출과 소형 모델(Qwen3-8B) 파인튜닝(SFT+RL) 경로를 비교하고, 소형 파인튜닝 경로가 대형 모델에 가깝거나 일부 시나리오에서 더 나은 결과를 보일 수 있음을 보고합니다.
이 말은 “작은 모델이 무조건 좋다”가 아니라, 업무가 좁고(정의 가능), 출력 형식을 고정할수록 소형 모델의 효율이 올라간다는 뜻입니다.
출력 형식을 고정하려면 스키마를 먼저 두는 편이 좋습니다. 분석→예측→결정을 이어 주는 템플릿은 JSON 스키마 템플릿으로 분석→예측→결정 연결하기에서 다룹니다. 환각을 줄이는 체크리스트는 용어·근거·형식 3가지만 고정하라에 정리되어 있습니다.
5) 리스크: 비용보다 더 크게 터지는 5가지
| 위험 신호 | 완화책 |
|---|---|
| 모델 드리프트(업데이트) | 회귀테스트·리플레이로 출력 변경 감지; 버전 고정·재학습 주기 문서화 |
| 벤더 락인 | 추상화 레이어·다중 백엔드; 캐시/배치 설계를 API에 비의존적으로 |
| 레이트리밋·장애 | 라우팅 폴백(저가 모델/캐시)·캐시/배치로 피크 분산; “늦어도 실패” 구간 식별 |
| 데이터·보안 | 권한분리·입력 마스킹; 민감 데이터는 자체 호스팅 검토 |
| 운영 난이도 | 서빙/모니터링/업데이트 비용을 인력·역량에 맞게 산정; 리플레이·회귀테스트 루틴 고정 |
실거래 연결 단계라면 특히 Account State & Execution 레이어 설계: “결정”을 “주문”으로 바꾸는 마지막 1단계를 참고하세요.
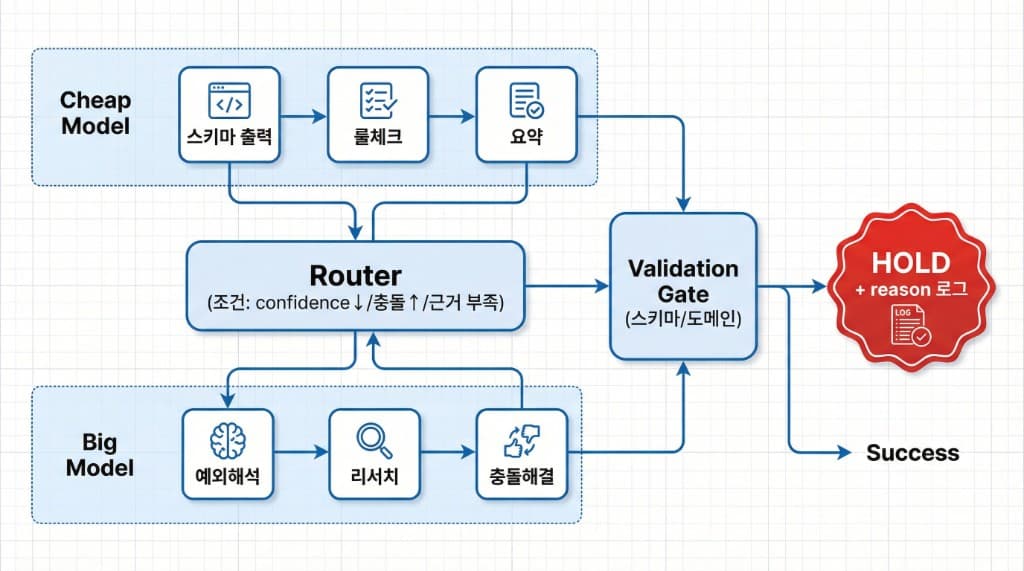
6) “하이브리드(라우팅)”가 가장 많이 이기는 이유
한 줄로 말하면: 비싼 모델은 “어려운 순간”에만 쓰고, 나머지는 싼 모델이 처리하게 만들면 된다.
- 소형(또는 파인튜닝) 모델: 스키마 출력, 신호 요약, 룰 체크, 포지션 이산 액션 생성
- 대형 모델: 충돌 해결, 예외 케이스 해석, 리서치/설명 생성(감사 로그용)
또한 API만 쓰더라도 배치/캐시로 비용을 크게 줄일 수 있습니다.
FAQ
자주 묻는 질문
- "월간 얼마 이상이면" 파인튜닝이 무조건 이득인가요?
- 정답은 월 토큰량이 아니라 "업무의 고정도(규칙화 가능성) + 운영 역량"입니다. 먼저 로그로 Tin/Tout, 호출 구조(에이전트 수)를 측정하세요.
- 파인튜닝 없이 소형 모델만 바꿔도 되나요?
- 가능합니다. 다만 트레이딩은 "정확도"보다 형식 준수/재현성/제약 준수가 중요해서, 파인튜닝보다 먼저 스키마/검증 게이트/로그를 고정하는 게 보통 더 큰 효과를 냅니다.
- 비용 최적화의 1순위는 뭔가요?
- 대부분 토큰 절감(요약/캐시/중복 호출 제거)이 1순위이고, 그 다음이 라우팅/배치, 마지막이 "모델 자체 교체"입니다.
결론: 선택 기준은 “가격표”가 아니라 “호출 구조 + 로그”다
- 내 시스템의 월 Tin/Tout/호출 수를 로그로 뽑고
- API 비용식을 대입해 “현재 비용”을 확정한 뒤
- (규칙화 가능하면) 라우팅/파인튜닝으로 고정비 모델을 검토하세요.
그리고 어떤 선택이든 리플레이/회귀 테스트가 없으면 모델 교체는 리스크가 됩니다.